I’ve never been a very mathy person, and I came to trigonometry particularly late in life—surprisingly so, considering I’m a programmer who has to draw graphics from time to time. (Guess why I started learning it.)
So, for folks like me who can’t read Greek, here’s an introduction to trigonometry.
Trigonometry largely revolves around three basic functions:
You know these from the famous mnemonic acronym “SOHCAHTOA”, which is where I’ll start from.
The acronym summarizes the three functions thusly:
- sine = opposite / hypotenuse
- cosine = adjacent / hypotenuse
- tangent = opposite / adjacent
Very buzzwordy, and nonsensical when every time you use them, you pass in an angle. And yet, 100% correct.
The cosine, sine, and tangent functions work by creating an imaginary triangle whose hypotenuse has the given angle, and returning the ratio of two of that triangle’s sides.
Given the angle of 30° (or π × 30⁄180 radians, or τ × 30⁄360 radians):

All three functions create this triangle, and then return the ratio of two of its sides.
Note the proximity of the three sides to the origin.
- The opposite side is the vertical side, literally on the opposite side of the triangle from the origin.
- The adjacent side is the horizontal side, extending from the origin to the opposite side. It’s the adjacent side because it touches (is adjacent to) the origin.
- The hypotenuse is the (usually) diagonal side that extends from one end of the adjacent side (namely, from the origin) to one end of the opposite side (namely, the end that isn’t touching the other end of the adjacent side).
Let’s consider a different case for each function—namely, for each function, the case in which it returns 1.
Cosine
Definition: adjacent / hypotenuse
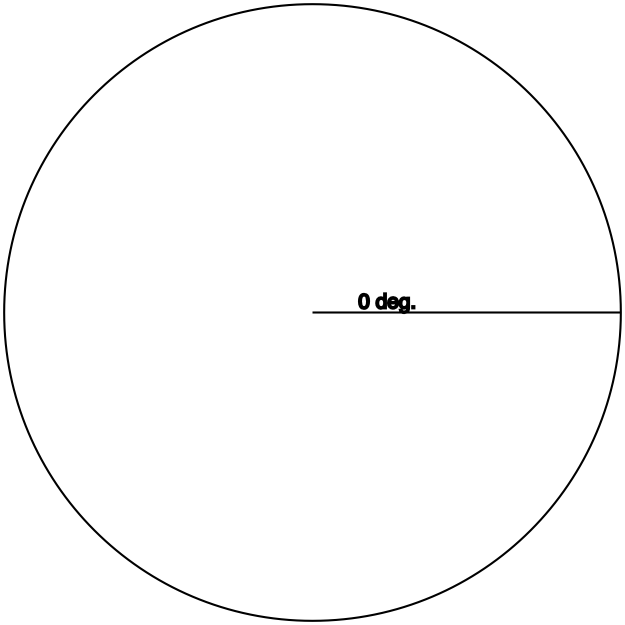
With the hypotenuse at 0°, there basically is no opposite side: The hypotenuse is in exactly the same space as the adjacent side, from the origin to the lines’ ends. Thus, they are equal, so the ratio is 1.
Sine
Definition: opposite / hypotenuse
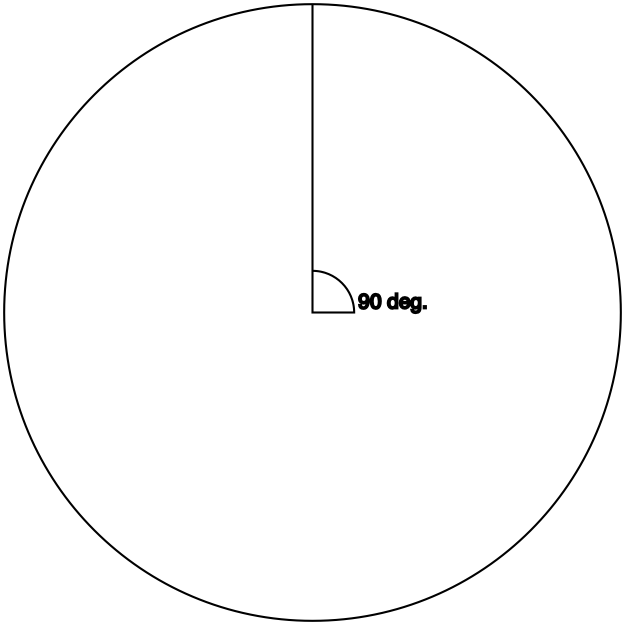
With the hypotenuse at 90° (or τ/4), there basically is no adjacent side: The hypotenuse is in exactly the same space as the opposite side, from the origin to the lines’ ends. Thus, they are equal, so the ratio is 1.
Cosine and sine: What if we swap them?
Try sin 0 or cos τ/4. What do you get?
Zero, of course. The 0° triangle has effectively no opposite side, so the sine of that (tri)angle is 0⁄1, which is zero.
Likewise, the 90° triangle has effectively no adjacent side, so the cosine (adjacent/hypotenuse) of that (tri)angle is 0⁄1.
Tangent
Definition: opposite / adjacent
You should be able to guess what the triangle for which tangent returns 1 looks like. Go on, take a guess before you scroll down.
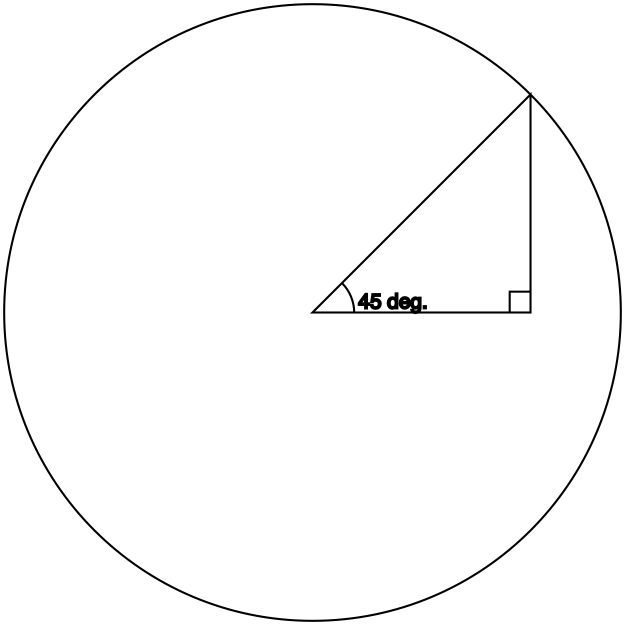
A 45° (tri)angle’s adjacent and opposite sides are equal, which is what makes the tangent function return 1.
Cosine and sine: The unit circle
Cosine and sine return the ratio of one side or the other to the hypotenuse.
Accordingly, the length of the hypotenuse affects the result. But, again, these functions take only an angle, so where do you tell it what hypotenuse to use? And why do these functions, on any calculator and in any programming language, return only a single number?
The trigonometric functions are defined in terms of the unit circle, which is a circle with radius 1.
If you look at the diagrams above, you’ll notice that the hypotenuse of the triangle always extends to the perimeter of the circle—that is, it’s always equal to the radius. This is no accident: The hypotenuse of the constructed triangle is the radius of the circle. And since the radius of the unit circle is 1, that means the hypotenuse of the imaginary triangle is 1.
Thus, the fractions that cosine and sine return are adjacent / 1 and opposite / 1. That’s why they return single numbers: the “/ 1” is simplified out.
From this follows the method to compute cosine or sine for an arc with a different radius: Multiply the cosine or sine by the desired radius.
Cosine and sine: What if we use an angle greater than 90°?
What happens if we take the cosine and sine of an angle like, say, 4 radians (about 230°)?
Let’s draw out the triangle:
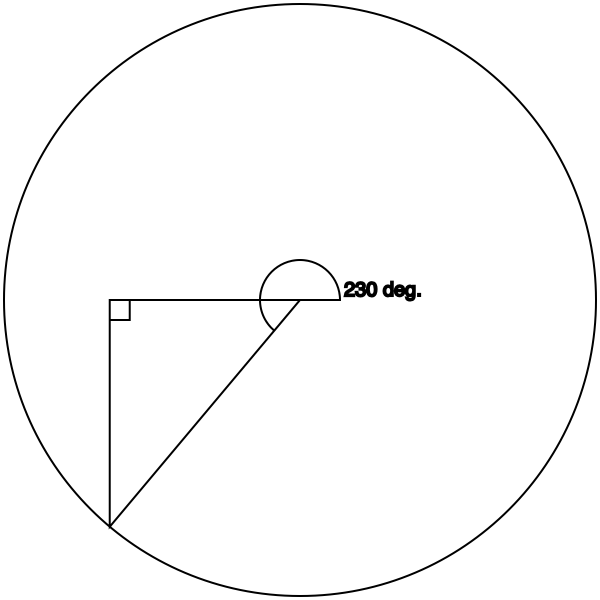
Geometrically, the origin is 0,0. As long as we’re in the 0–90° range, no problem, because both the x (cosine) and y (sine) values in that quadrant are positive. But now we’re in negative territory.
With the hypotenuse in this quadrant, the adjacent and opposite sides are now negative numbers. cos π = cos τ⁄2 is -1, and sin (τ×3⁄4) is likewise -1. For this triangle, they’re similarly negative, though not -1.
(Exercise: What about the other two quadrants? What are the cosine and sine of, say, 110° and 300°?)
Tangent: What if we use an angle greater than 45°?
As we saw above, if we give the tangent function an angle of τ/8, the ratio is 1. What if we go higher?
Well, then the ratio goes higher. Very quickly.
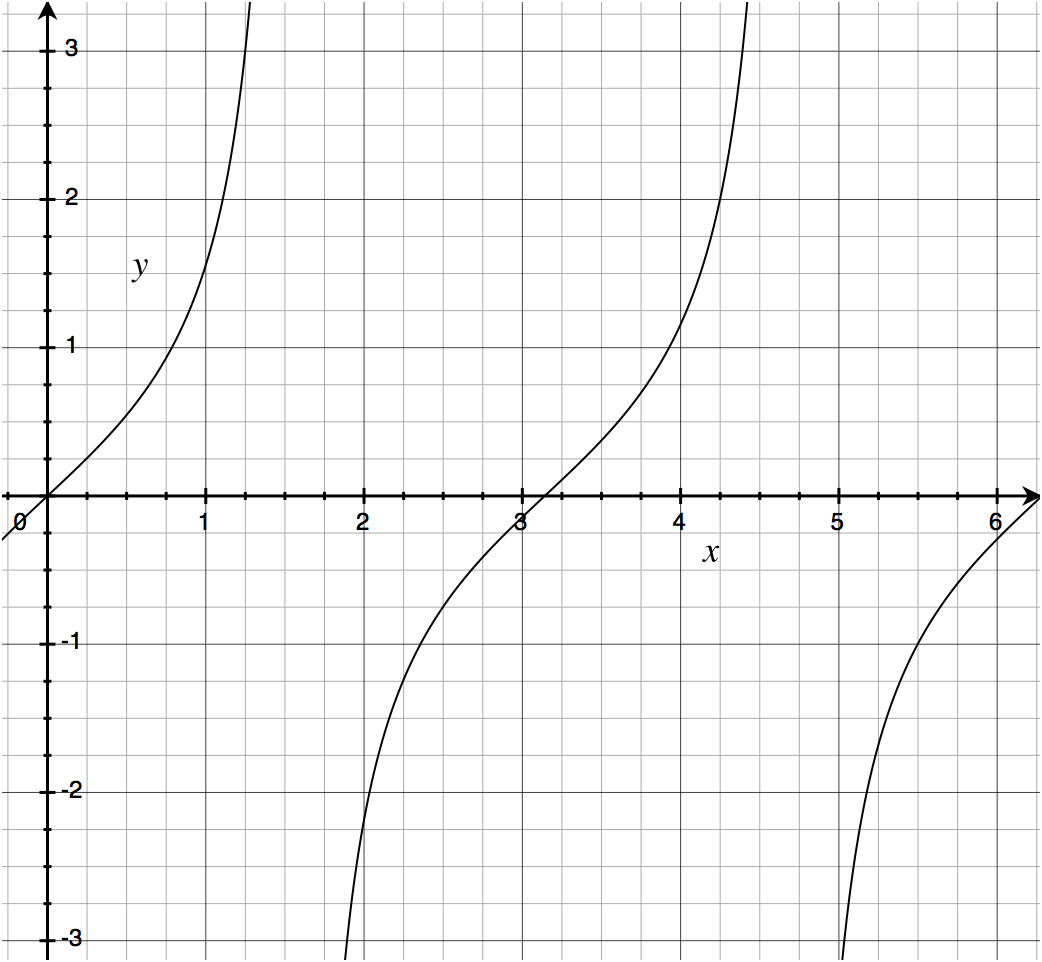
The half-curve at left is the quadrant from 0 to τ/4 (the upper-right quadrant).
The curve in the middle is the two quadrants from τ/4 to τ×3⁄4 (the entire left half of the circle).
The half-curve at right is the quadrant from τ×3⁄4 to τ (the lower-right quadrant).
In words, the tangent function returns a value from 0 to 1 (inclusive) for any angle that is a multiple of π plus or minus τ⁄4 (45°). 0 counts (it’s 0π), as does π, as does π2 (= τ = 360°), and so on. Likewise 45°, 360-45=315°, 180-45=135°, 180+45=215°, etc.
Outside of those left and right quadrants, the tangent function curves very quickly off the chart—it approaches infinity.
(Programmer note: In some environments, there are both positive and negative values of zero, in which case tan 0 returns positive zero and tan π returns negative zero. Mathematically, there is only one zero and it is neither positive nor negative.)
Tangent is the only one of the three that can barf on its input. Namely, a hypotenuse angle of τ/4 (90°) equates to the opposite (vertical) side being 1 and the adjacent (horizontal) side being 0 (as shown above for the sine function), so tan τ⁄4 = 1/0, which is undefined. The same goes for tan τ3⁄4, which equates to -1⁄0.
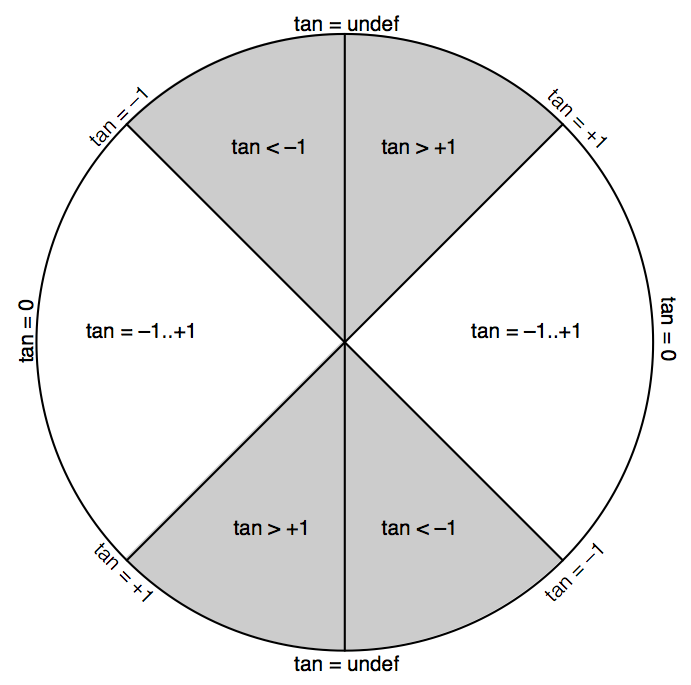
The tangent of an angle is its slope, which you can use to reduce an angle down to whether it is more horizontal (-1..+1), more vertical (< -1 or > +1), perfectly horizontal (0), or perfectly vertical (undefined).
As a practical matter, whenever I need to compute a slope ratio, I special-case perfectly vertical angles to result in ∞.
Cosine and sine: Width and height
From the above definitions, the practical use of cosine and sine emerges: They return the width and height of the right triangle whose hypotenuse has that angle.
As described above, these results are typically interpreted in terms of the unit circle (a circle with radius 1), meaning that the hypotenuse of the triangle is 1. Thus, if you’re working with an arc or circle with a different radius, you need to multiply your cosine or sine value by that radius.
A practical problem
For example, let’s say your friend has a 50″ TV, and you’re wondering what its width and height is. Maybe she’s moving, or giving or selling it to you, or both, so one of you is going to need to know whether and where it’ll fit.
The length of the hypotenuse is the radius of the circle; in the unit circle, it’s 1, but we’re dealing with a hypotenuse (diagonal measurement of the screen) whose length is something else. Our radius is 50″.
Next, we need the angle. No need for a protractor; TVs typically have an aspect ratio of either 16:9 (widescreen) or 4:3 (“standard”). The aspect ratio is width / height, which is the inverse of the slope ratio: the ratio that the tangent function gives us (which is opposite / adjacent, or height / width). Dividing 1 by the aspect ratio gives us the slope.
Only problem is now we need to go the opposite direction of tangent: we need to go from the slope ratio to the angle.
No problem! That’s what the atan (arctangent) function is for. (Each of the trigonometric functions has an inverse, with the same name but prefixed with “arc” for reasons I have yet to figure out.)
atan takes a slope ratio and gives us, in radians (fraction of τ), the angle that corresponds to it.
Let’s assume it’s an HDTV. (I don’t want to think about trying to move an old 50″ rear-projection SDTV.) The aspect ratio is 16/9, so the slope is 9/16 (remember, tangent is opposite over adjacent); atan 9⁄16 is about 29–30°, or about 0.5 radians.
I promise that my choice of 30° for the first example and subsequently deciding to measure an HDTV as the example use case was merely a coincidence.
So we have our angle, 0.5 radians, and our radius, which is 50″. From this, we compute the width and height of the television:
- Take the cosine and sine of the angle. (Roughly 0.867 and 0.577, respectively, but use your calculator.)
- Multiply each of these by 50 to get the width and height (respectively) in inches. (Roughly 44″ and 29″, respectively, rounding up for interior-decorative pessimism.)
- Add an inch or two to each number to account for the frame around the viewable area of the display.
So the TV needs about 45 by 30 inches of clear space in order to not block anything.










{kind=link}
{kind=link}
{kind=link}