A few weeks ago, I installed Adobe Reader to view a particular PDF, and noticed something interesting in its Preferences:
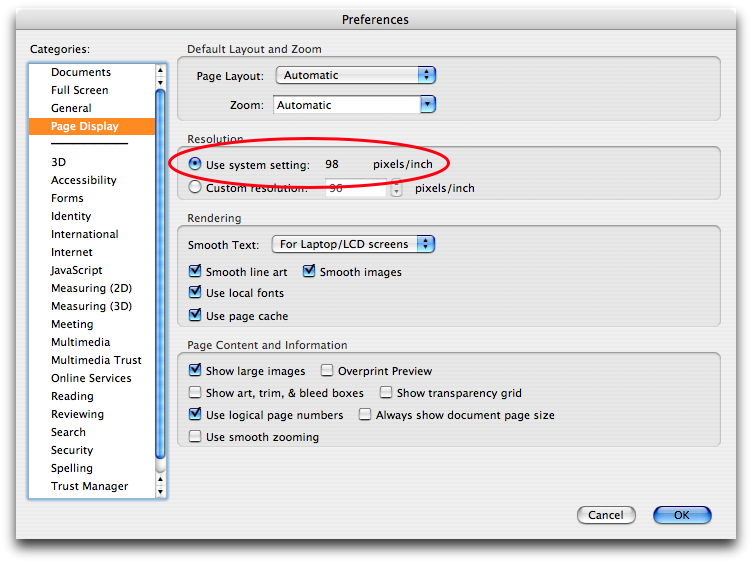
“Wow”, I thought, “I wonder how it knows that.” So I went looking through the Quartz Display Services documentation, and found it.
The function is CGDisplayScreenSize. It returns a struct CGSize containing the number of millimeters in each dimension of the physical size of the screen. Convert to inches and divide the number of pixels by it, and you’ve got DPI.
Not all displays support EDID (which is what the docs for CGDisplayScreenSize say it uses); if yours doesn’t, CGDisplayScreenSize will return CGSizeZero. Watch for this; failure to account for this possibility will lead to division-by-zero errors.
Here’s an app to demonstrate this technique:
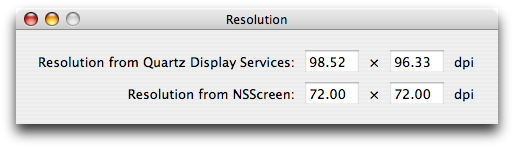
ShowAllResolutions will show one of these windows on each display on your computer, and it should update if your display configuration changes (e.g. you change resolution or plug/unplug a display). If CGDisplayScreenSize comes back with CGZeroSize, ShowAllResolutions will state its resolution as 0 dpi both ways.
The practical usage of this is for things like Adobe Reader and Preview (note: Preview doesn’t do this), and their photographic equivalents. If you’re writing an image editor of any kind, you should consider using the screen resolution to correct the magnification factor so that a 8.5×11″ image takes up exactly 8.5″ across (and 11″ down, if possible).
“Ah,”, you say, “but what about Resolution Independence?”.
The theory of Resolution Independence is that in some future version of Mac OS X (possibly Leopard), the OS will automatically set the UI scale factor so that the interface objects will be some fixed number of (meters|inches) in size, rather than some absolute number of pixels. So in my case, it would set the UI scale factor to roughly 98/72, or about 1+⅓.
This is a great idea, but it screws up the Adobe Reader theory of automatic magnification. With its setting that asks you what resolution your display is, it inherently assumes that your virtual display is 72 dpi—that is, that your UI is not scaled. Multiplying by 98/72 is not appropriate when the entire UI has already been multiplied by this same factor; you would essentially be doing the multiplication twice (the OS does it once, and then you do it again).
The solution to that is in the bottom half of that window. While I was working on ShowAllResolutions, I noticed that NSScreen also has a means to ascertain the screen’s resolution: [[[myScreen deviceDescription] objectForKey:NSDeviceResolution] sizeValue]. It’s not the same as the Quartz Display Services function, as you can see; it seemingly returns { 72, 72 } constantly.
Except it doesn’t.
In fact, the size that it returns is premultiplied by the UI scale factor; if you set your scale factor to 2 in Quartz Debug and launch ShowAllResolutions, you’ll see that NSScreen now returns { 144, 144 }.
The Resolution-Independent version of Mac OS X will probably use CGDisplayScreenSize to set the scale factor automatically, so that on that version of Mac OS X, NSScreen will probably return { 98.52, 98.52 }, { 96.33, 96.33 }, or { 98.52, 96.33 } for me. At that point, dividing the resolution you derived from CGDisplayScreenSize by the resolution you got from NSScreen will be a no-op, and the PDF view will not be doubly-magnified after all. It will be magnified by 133+⅓% by the UI scale factor, and then magnified again by 100% (CGDisplayScreenSize divided by NSDeviceResolution) by the app.
Obviously, that’s assuming that the app actually uses NSScreen to get the virtual resolution, or corrects for HIGetScaleFactor() itself. Adobe Reader doesn’t do that, unfortunately, so it suffers the double-multiplication problem.
So, the summary:
- To scale your drawing so that its size matches up to real-world measurements, scale by NSDeviceResolution divided by
{ 72.0f, 72.0f }. For example, in my case, you would scale by { 98.52, 96.33 } / { 72.0, 72.0 } (that is, the x-axis by 98.52/72 and the y-axis by 96.33/72). The correct screen to ask for its resolution is generally [[self window] screen] (where self is a kind of NSView).
- You do not need to worry about HIGetScaleFactor most of the time. It is only useful for things like
-[NSStatusBar thickness], which return a number of pixels rather than points (which is inconvenient in, say, your status item’s content view).