The design for LMX 2.0
LMX 1.0 didn’t really have much design to it. I set out to clone NSXMLParser‘s API, which I did, but didn’t give a whole lot of thought to how I would actually implement the parser.
As a result, the parser itself is one humongous method that takes a lot of effort to read. It is only navigable at all because I had the foresight to put in lots of #pragma marks.
LMX 2.0 will not make that mistake. This time, there’s a design, and the parser will not all be in one function. Here’s the design, which I drew on a quadrille pad:
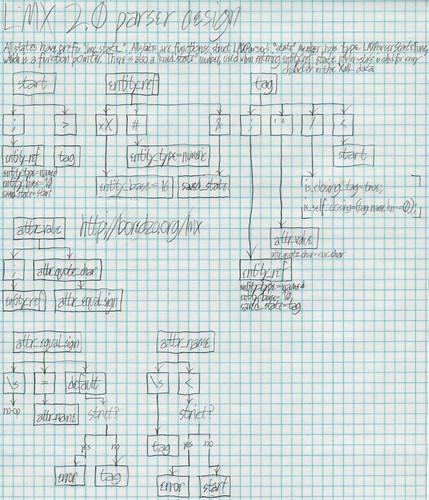
To be explicit, these are all implementation details which will not be exposed to clients of the API.
And the scanner I used to import this from dead tree format is the CanoScan LiDE 600F I mentioned in passing in my post about my HP M425 camera.
March 13th, 2007 at 16:42:50
Want me to graffle this up for you?
March 13th, 2007 at 17:05:56
Please do. :)
March 14th, 2007 at 01:01:05
One huge method…what were you thinking man?
/me points Boredzo @ Refactoring by Martin Fowler.
I’ve never again written a huge method since I read that book. Thinking about it its probably time for another read again…